

Cybersecurity is a rising and never-ending concern for any information technology professional across the industry. There is one threat that is of particular concern for server operators, specifically web server operators. That is the threat of scanner-bots. These bots scan web servers for common web-based apps with known security exploits. If an exploit is found it will report the information to the individual or group responsible for deploying the bot. Knowing this vulnerability, the individual or group could perform an attack on the server and cause as much damage as the exploit and server configuration permits.
Web servers can be configured to log the traffic that they receive on a daily basis. This traffic data could then be analyzed for a number of purposes. The purpose that is most interesting is the identification of a bot versus a person. If a bot is identified actions could be taken to block the bot before it can execute the scan and execute a malicious attack.
Data Processing
The dataset started off as Apache web server logs. In this format the data was not very useful and difficult for analysis. This log provides a number of variables, but these variables are all encoded in a way that is sufficient for storing in a log file on a server. To produce something that is better suited for analysis a script was created to decode the dataset into a more suitable format.
In the new processed dataset, there is a flag to indicate whether a bot identified itself as a bot when it made a request against the server. A valid bot must provide this flag, so a web server can decide how to handle traffic delivered to the bot. If a record does not have this flag, it is unknown if the request is from a bot or not. For instance, a search bot may not need to have images sent when the page is requested, since it is most likely only concerned with the textual content of the site, thus saving on bandwidth. Legitimate bots could be the key to identifying malicious bots in the log files. Since they should show similar behaviors, unlike a person browsing the website.
The Code
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import pytz
import re
import socket
import struct
from datetime import datetime
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN
from sklearn.cluster import AffinityPropagation
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import normalize
from sklearn.decomposition import PCA
from sklearn import metrics
from user_agents import parse
def parse_str(x):
"""
Returns the string delimited by two characters.
Source: https://mmas.github.io/read-apache-access-log-pandas
Example:
`>>> parse_str('[my string]')`
`'my string'`
"""
return x[1:-1]
def parse_datetime(x):
'''
Parses datetime with timezone formatted as:
`[day/month/year:hour:minute:second zone]`
Source: https://mmas.github.io/read-apache-access-log-pandas
Example:
`>>> parse_datetime('13/Nov/2015:11:45:42 +0000')`
`datetime.datetime(2015, 11, 3, 11, 45, 4, tzinfo=<UTC>)`
Due to problems parsing the timezone (`%z`) with `datetime.strptime`, the
timezone will be obtained using the `pytz` library.
'''
dt = datetime.strptime(x[1:-7], '%d/%b/%Y:%H:%M:%S')
dt_tz = int(x[-6:-3])*60+int(x[-3:-1])
return dt.replace(tzinfo=pytz.FixedOffset(dt_tz))
def parse_logfile(x):
'''
Parses log file and returns pandas dataframe
Example:
`>>> data = parse_logfile('/path/to/file')`
'''
return pd.read_csv(
x,
sep=r'\s(?=(?:[^"]*"[^"]*")*[^"]*$)(?![^\[]*\])',
engine='python',
na_values='-',
header=None,
usecols=[0, 3, 4, 5, 6, 7, 8],
names=['ip', 'time', 'request', 'status', 'size', 'referer', 'user_agent'],
converters={'time': parse_datetime,
'request': parse_str,
'status': int,
'size': int,
'referer': parse_str,
'user_agent': parse_str})
#Convert IP Address to decimal format
def ip_to_dec(x):
return int(bin(struct.unpack('!I', socket.inet_aton(x))[0]), 2)
#Parse user agent and break it into parts for analysis
def parse_user_agent(x):
try:
user_agent = parse(x)
return user_agent.is_mobile, user_agent.is_tablet, user_agent.is_pc, user_agent.is_touch_capable, user_agent.is_bot, user_agent.browser.family, user_agent.browser.version_string, user_agent.os.family, user_agent.os.version_string, user_agent.device.family, user_agent.device.brand, user_agent.device.model
except:
return 0, 0, 0, 0, 0, "", "", "", "", "", "", ""
#Parse the status and break it into parts for analysis
def parse_status(x):
'''
200 - ok
206 - partial_content
301 - moved_permanently
302 - found
304 - not_modified
400 - bad_request
401 - unauthorized
403 - forbidden
404 - not_found
405 - method_not_allowed
408 - request_timeout
503 - service_unavailable
'''
codes = [200, 206, 301, 302, 304, 400, 401, 403, 404, 405, 408, 503]
index = 0
results = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
for code in codes:
if code == x:
results[index] = 1
break #exit loop once the match is found
index = index + 1
return results
#Parse the request from the access log and break it into parts that can be used for analysis
def parse_request(x):
'''
GET
HEAD
OPTIONS
POST
PROPFIND
PUT
METHOD_UNKNOWN
HTTP
HTTP/1.0
HTTP/1.1
PROTOCOL_UNKNOWN
'''
codes = ['GET', 'HEAD', 'OPTIONS', 'POST', 'PROPFIND', 'PUT', 'METHOD_UNKNOWN', 'HTTP', 'HTTP/1.0', 'HTTP/1.1', 'PROTOCOL_UNKNOWN']
results = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, '']
index = 0
try:
split = x.split(' ')
for code in codes:
if code == split[0]:
results[index] = 1
if code == split[2]:
results[index] = 1
index = index + 1
results[index] = split[1]
return results
except:
return [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, x]
#Read log files
data = parse_logfile('../data/access.log')
#Get rid of internal requests
data = data[data.ip != "::1"]
#Convert time to fields
data['timeYear'] = data.time.dt.strftime('%Y')
data['timeMonth'] = data.time.dt.strftime('%m')
data['timeDay'] = data.time.dt.strftime('%d')
data['timeHour'] = data.time.dt.strftime('%H')
data['timeMinute'] = data.time.dt.strftime('%M')
#Parse user agent
data[['user_agent_is_mobile', 'user_agent_is_tablet', 'user_agent_is_pc', 'user_agent_is_touch_capable', 'user_agent_is_bot', 'user_agent_browser_family', 'user_agent_browser_version_string', 'user_agent_os_family', 'user_agent_os_version_string', 'user_agent_device_family', 'user_agent_device_brand', 'user_agent_device_model']] = pd.DataFrame(data['user_agent'].apply(parse_user_agent).tolist(), index=data.index)
data[['ok', 'partial_content', 'moved_permanently', 'found', 'not_modified', 'bad_request', 'unauthorized', 'forbidden', 'not_found', 'method_not_allowed', 'request_timeout', 'service_unavailable']] = pd.DataFrame(data['status'].apply(parse_status).tolist(), index=data.index)
data[['GET', 'HEAD', 'OPTIONS', 'POST', 'PROPFIND', 'PUT', 'METHOD_UNKNOWN', 'HTTP', 'HTTP/1.0', 'HTTP/1.1', 'PROTOCOL_UNKNOWN', 'requested_page']] = pd.DataFrame(data['request'].apply(parse_request).tolist(), index=data.index)
data.to_csv(r'processed.csv')
#print(data.groupby(['ip', 'timeYear', 'timeMonth', 'timeDay', 'timeHour', 'timeMinute', 'status', 'user_agent']).count())
#print(data.groupby(['ip', 'timeYear', 'timeMonth', 'timeDay', 'timeHour', 'timeMinute', 'status', 'user_agent']).sum())
#print(data.columns)
import graphviz
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import pytz
import re
import scipy.stats as stats
import socket
import struct
from datetime import datetime
from factor_analyzer import FactorAnalyzer
from sklearn import tree
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN
from sklearn.cluster import AffinityPropagation
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import normalize
from sklearn.decomposition import PCA
from sklearn import metrics
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
#Load Dataset
VariableData = pd.read_csv('processed.csv')
#Exclude text columns
ReducedData = VariableData.iloc[:,14:]
ReducedData['ip'] = VariableData['ip']
#Remove all records with na data
ReducedData = ReducedData.dropna()
#Group Data for summization based on time and source
#A.groupby('Name').agg({'Missed':'sum','Credit':'sum','Grades':'mean'})
GroupData = ReducedData.groupby(['ip', 'timeYear', 'timeMonth', 'timeDay', 'timeHour', 'timeMinute']). \
agg({'user_agent_is_bot':'max', 'user_agent_is_bad_bot':'max', 'num_request':'sum', 'size':'mean', \
'user_agent_is_mobile':'sum', 'user_agent_is_tablet':'sum', \
'user_agent_is_pc':'sum', 'user_agent_is_touch_capable':'sum', 'ok':'sum', \
'partial_content':'sum', 'moved_permanently':'sum', 'found':'sum', 'not_modified':'sum', \
'bad_request':'sum', 'unauthorized':'sum', 'forbidden':'sum', 'not_found':'sum', \
'method_not_allowed':'sum', 'request_timeout':'sum', 'service_unavailable':'sum', 'GET':'sum', \
'HEAD':'sum', 'OPTIONS':'sum', 'POST':'sum', 'PROPFIND':'sum', 'PUT':'sum', 'METHOD_UNKNOWN':'sum', \
'HTTP':'sum', 'HTTP/1.0':'sum', 'HTTP/1.1':'sum', 'PROTOCOL_UNKNOWN':'sum'}).reset_index()
#Randomly select 80% of data set
PopCount = GroupData['size'].count()
SampleCountF = PopCount * 0.15
SampleCount = int(round(SampleCountF))
TrainingData = GroupData.sample(SampleCount)
#Get test data by crossing sample data with the original data set
TestData = pd.DataFrame(GroupData[~GroupData['size'].index.isin(TrainingData['size'].index)])
#Data Counts for verification of data division
print("Population Count: %s" % GroupData['user_agent_is_bad_bot'].count())
print("Training Count: %s" % TrainingData['user_agent_is_bad_bot'].count())
print("Test Count: %s" % TestData['user_agent_is_bad_bot'].count())
#Create decision tree classifier and fit the data set
X = TrainingData.drop(['user_agent_is_bad_bot', 'user_agent_is_bot', 'ip'], axis=1)
#Training using traffic identified as malicious
Y = TrainingData['user_agent_is_bad_bot']
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)
#Check test data and determine accuracy
P = TestData.drop(['user_agent_is_bad_bot', 'user_agent_is_bot', 'ip'], axis=1)
TestData['Predicted_Bot'] = clf.predict(P)
TestData['Bots_Predicted_Positive'] = TestData['Predicted_Bot'] & TestData['user_agent_is_bad_bot']
TestData['Bots_Predicted_False_Negative'] = ~TestData['Predicted_Bot'] & TestData['user_agent_is_bad_bot']
TestData['Bots_Predicted_False_Positive'] = TestData['Predicted_Bot'] & ~TestData['user_agent_is_bad_bot']
print('Predicted number of bots: %s' % TestData['Predicted_Bot'].sum())
print('Bots correctly predicted: %s' % TestData['Bots_Predicted_Positive'].sum())
print('Falsely identified bot: %s' % TestData['Bots_Predicted_False_Negative'].sum())
print('Falsely identified not bot: %s' % TestData['Bots_Predicted_False_Positive'].sum())
#Mean requests per minute for malicous bots
BadBotMean = TestData[TestData.Bots_Predicted_Positive == 1]['num_request'].mean()
print("Bad bots: %s" % BadBotMean)
#Mean requests per minute for good bots
GoodBotMean = TestData[TestData.user_agent_is_bot == 1]['num_request'].mean()
print("Good bots: %s" % GoodBotMean)
#Perform T-Test
t, p = stats.ttest_1samp(TestData[TestData.Bots_Predicted_Positive == 1]['num_request'], GoodBotMean)
print("T %s" % t)
print("P %s" % p)
#Confusion Matrix
cm=confusion_matrix(TestData['user_agent_is_bad_bot'], TestData['Predicted_Bot'])
print(cm)
#BOT Ip Address
print(TestData[TestData.Bots_Predicted_Positive == 1]['ip'])
#Render tree
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("BotTree")
#graph.view("BotTree")
#Check regression of bot activity over the time period of the log data
RequestData = TestData[TestData.Bots_Predicted_Positive == 1].sort_values(by=['timeYear', 'timeMonth', 'timeDay', 'timeHour', 'timeMinute'])
RequestData = RequestData.loc[:,['timeDay', 'num_request']]
results = stats.linregress(RequestData['timeDay'], RequestData['num_request'])
print(results)
x = RequestData.iloc[:, :-1].values
y = RequestData.iloc[:, 1].values
reg = LinearRegression().fit(x,y)
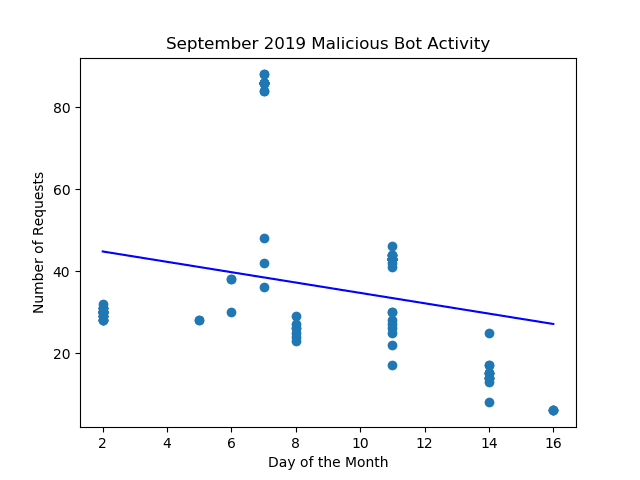
#estimated number of attacks for September 15
y1 = reg.predict([[15]])
print("Estimated number of attacks for September 15, 2019: %s " % y1)
#Label Axis
plt.title('September 2019 Malicious Bot Activity')
plt.xlabel('Day of the Month')
plt.ylabel('Number of Requests')
#Plot the Data
plt.scatter(x=x,y=y)
plt.plot(x,reg.predict(x),color = 'blue')
plt.show()
Results
Population Count: 10661 Training Count: 1599 Test Count: 9062 Predicted number of bots: 145 Bots correctly predicted: 98 Falsely identified bot: 64 Falsely identified not bot: 47
At first glance, there seems to be an almost 70% success chance of identifying malicious bots correctly. Upon further inspection however, there is a much lower success chance. This is due to traffic accidentally getting classified as a bot when it should not have or vice-versa. A larger dataset of web traffic data could fix this issue. As the model is trained to recognize the proper behaviors.
The preliminary data analysis certainly provides information pointing in the right direction. There are a few concerns before absolutely confirming the techniques used in the classification of the server traffic. The first is traffic that is falsely identified as malicious. Increased data could help reduce the number of requests identified as not a malicious bot. People make mistakes accessing web pages directly or site owner could setup a link incorrectly. These accidents can lead to mis-identification of web traffic. A larger data set with could help distinguish these one-off events from malicious bots making a series of requests all at once. The next concern is ensuring that good bots are not blocked. Google’s search engine spider crawls the web constantly ensuring they have up to date data. Blocking Google from accessing your web site could seriously harm the accessibility of the web site. The promising thing is thanks to the rules put forth by w3c, good spiders must identify themselves, and when you compare the self-identifying good bots to the bad one. There is a clear distinction. Finally, the most promising result is the indication that malicious activity is on somewhat of a decline. As web site requestors are identified as malicious or not and blocked accordingly. The regression analysis of the traffic data would continue to show a downward trend. This would be a great indication that they correct web traffic is being blocked.